Software Layer for an Urban Air Monitoring System
May 31, 2026 · Services: Data · Legacy Perl
In the mid-2010s, I worked on the software layer of a project connected with Saint Petersburg's urban air monitoring infrastructure. This was not ordinary web development. It was part of a city-scale infrastructure: automated stations across districts, gas analyzers, regular measurements, data transfer to a collection and processing center, measurement storage, and publication of information.
In practice, it was an industrial system with physical instruments and remote data collection before the term "Internet of Things" became mainstream. The system had real devices, COM ports, modem communication, intermediate measurement files, central processing, reporting, and reliability requirements. My work covered one software layer of an already existing urban infrastructure: the whole system was not built from scratch, but the station-side software had to become more maintainable.
Figure 1. Map with air monitoring station points, photographed in the project office. These physical observation points were the main data source for the software layer.
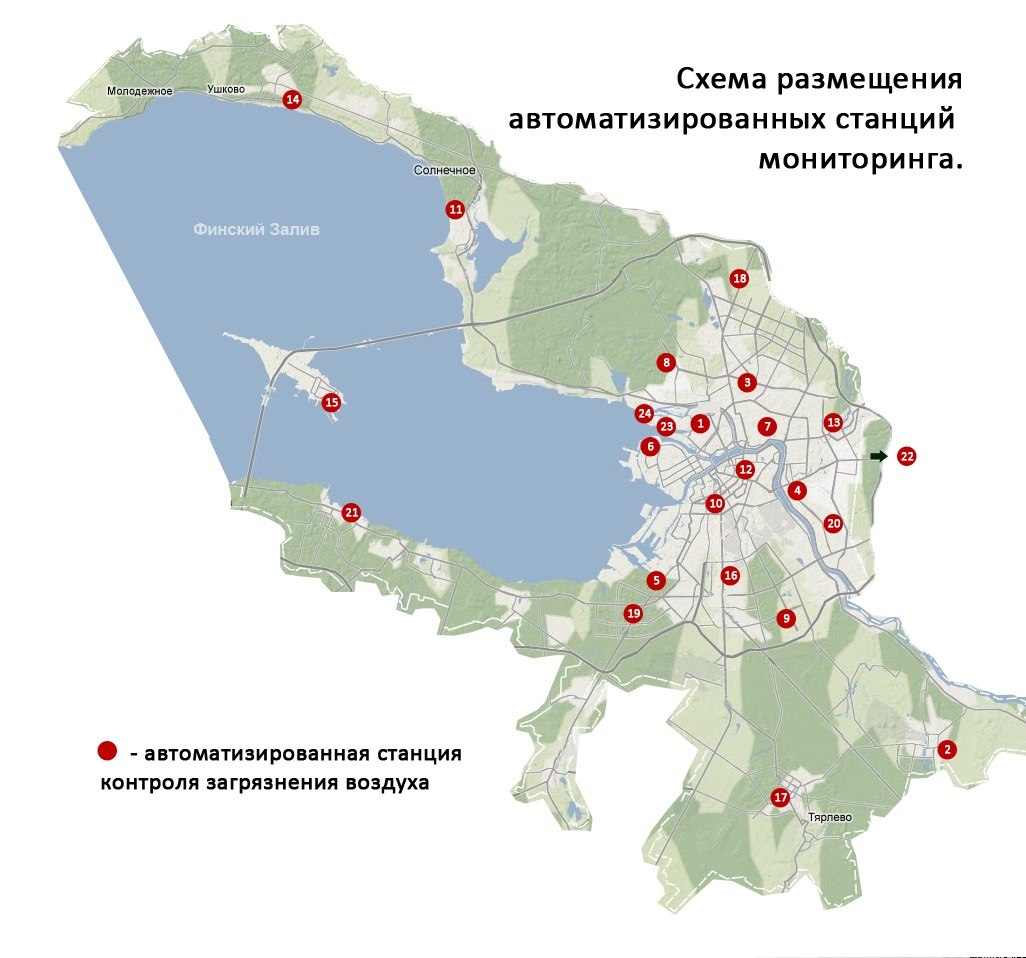
Figure 2. The same logic on the public side: a website map where station data became a readable city interface.
System Context
The city system was used for environmental monitoring of atmospheric air. Automated stations continuously measured pollutants, and results were sent at regular intervals to a central database for processing, reporting, and public information.
In systems like this, the software layer does not work with abstract form submissions. It works with a stream of physical measurements. On one side there are instruments, sensors, ports, modems, local files, and engineers who visit the station. On the other side there is central processing, storage, data quality control, and publication of results.
The system automatically measured carbon monoxide, nitric oxide, nitrogen dioxide, PM10 particulate matter, and sulfur dioxide. Benzene, toluene, ethylbenzene, xylenes, and phenol were monitored in a non-automated mode. Some of these measurements could involve semi-automatic sampling followed by laboratory analysis.
Initial State
At the time of my work, the main problem was not only the code, but also the way it was operated. The software was already running in production, but it had almost no proper engineering framework around it: no sufficient documentation, no reproducible deployment process, no clear change history, and no careful delivery process for updates.
This is common in long-running industrial systems. Code lives close to the equipment, changes are made as problems appear, part of the knowledge stays with individual people, and documentation appears later than the system itself. While everything works, this may look acceptable. But replacing a station, sending an engineer on site, connecting a new instrument, or fixing a bug becomes a manual operation with high risk.
What Had to Be Done
- Move the working code into a repository and make it the primary source.
- Describe the change process: tasks, branches, commits, checks, and promotion to production.
- Prepare documentation for the station-side setup: OS installation, environment, instrument configuration, service startup, backups, and code updates.
- Simplify station maintenance for engineers who visit a site and need to understand quickly what to update and how.
- Bring interns and junior specialists into the work so they could help with documentation, checks, and knowledge transfer without breaking production.
- Keep the existing system operational: this was infrastructure work, not a greenfield project where everything could be rewritten.
Repository, Documentation, Delivery
The first layer of work was organizational and engineering-oriented: make the code and documentation livable. A task-based process with separate branches was introduced for changes. Commits were tied to tasks, changes were tested before merging, and the master branch was treated as the production-ready version that could be installed on a working station.
This was not modern cloud CI/CD with containers, staging clusters, and automatic deployment to every station. Stations could have connectivity limits, and some updates were performed on site. But it was an important step toward controlled delivery: the code stopped being a set of files "somewhere in production", change history appeared, rules for promotion to production appeared, a test station appeared, and there was a clear way to update working stations from the repository.
Separate operational documentation was prepared: how to set everything up, which working directories are needed, where configuration files live, how to map instruments to ports, how to run real-time monitoring, how to configure measurement backups, and how to start station processes on boot.
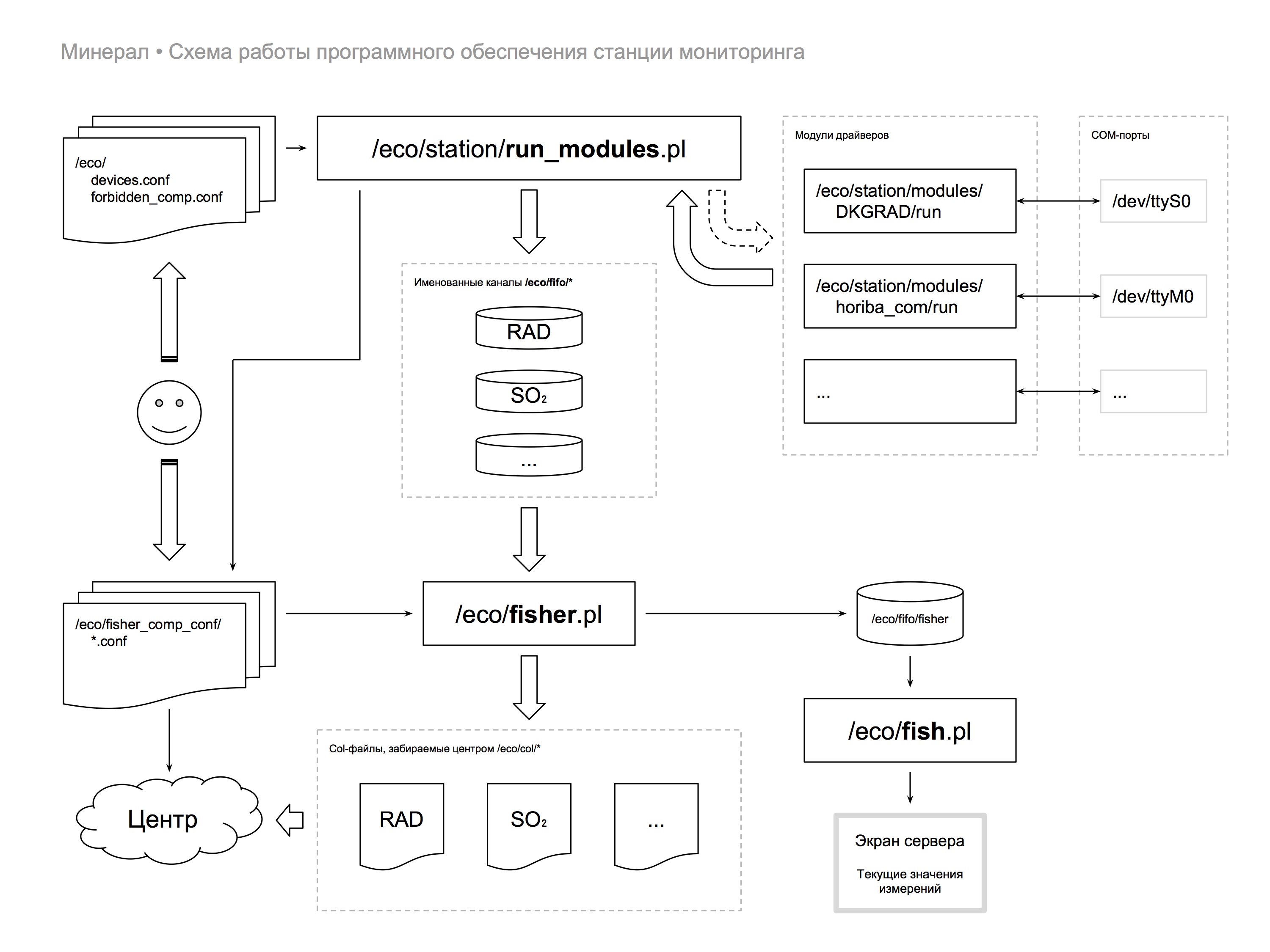
Figure 3. Software workflow diagram for a monitoring station from project working materials.
Station-Side Software
A station was not an abstract "API client", but a computer next to measurement equipment. Gas analyzers, weather sensors, radiation sensors, and service equipment were connected to it. A large part of the exchange used serial ports, so the documentation separately described MOXA boards for expanding the number of COM ports and mapping specific instruments to specific devices such as /dev/ttyM0, /dev/ttyM3, or /dev/ttyS0.

Figure 4. This is what a monitoring station looked like from the outside: a separate piece of city infrastructure visited by engineers for equipment and software maintenance.

Figure 5. Inside the station: a rack with measurement and service equipment, next to which the station-side software was running.
The working materials described different classes of instruments: ThermoElectron, Environnement, Horiba, Automet, WXT520, DKGRAD, and FDS. For them, measured parameters and units were recorded: NO, NO2, SO2, CO, O3, PM10/PM2.5, temperature, humidity, pressure, wind speed and direction, and radiation background. This shows the nature of the task: the software layer had to be a reliable intermediary between physical instruments and downstream data processing.
Data was not read from a polished screen interface, but from a port: raw values that had to be read correctly, normalized, stored, and transferred further.

Figure 6. Instrument readings at a station: NO, NO2, and NOx in mg/m³.
Inside the station-side software, there were separate processes for data collection and control. Measurement results were written to working directories, and the center could collect prepared files. For an engineer at the station, reproducible commands mattered: what to run, where to view live readings, how to check a port, and how not to lose data after a reboot.

Figure 7. Besides fixed stations, there was also a mobile station. It had a similar equipment rack inside, so the software maintenance requirements stayed just as practical: ports, instruments, configuration, data collection, and result transfer.
Tiny Core Linux
A separate part of the project was the station operating system based on Tiny Core Linux. It was a pragmatic choice for field conditions: the system booted from a flash drive, ran in RAM, and allowed the required configuration to be saved back to the drive. This simplified station maintenance and reduced dependence on local disk state.
The working station environment included Perl, git, minicom, pppd, inetutils, Log::Log4perl, JSON, and additional packages for serial-port work. Some dependencies had to be built and packaged separately for Tiny Core, including Perl modules for SerialPort and BufferedSelect, MOXA drivers, mgetty, and Vim. This was low-level operational work: not just writing a script, but making sure it started after a station reboot and kept working next to the instruments.
Working With the Team
Another part of the result was bringing people into the project. When a system exists only as production code and oral knowledge, an intern or junior developer cannot be included safely. First, the boundaries have to be described: where the documentation is, where the repository is, how tasks are created, what can be changed, what is checked on the test station, and what a working update looks like.
After that, interns could take limited tasks: clean up instructions, check deployment steps, record setup procedures, clarify configs, and help move knowledge into README files. For an industrial system with inherited code, this is not secondary work. It is a way to reduce dependence on one person and make maintenance more stable.
Result
- The station-side code was moved into a repository and became a managed artifact, not a set of files in production.
- The change process was described: tasks, branches, commits, testing, and promotion to the production branch.
- Operational documentation appeared for Tiny Core Linux, packages, boot startup, ssh, cron, backups, and station-to-center communication.
- Configuration principles were documented for instruments, ports, ignored measurements, and station process startup.
- The project became easier to hand over to engineers and junior specialists: part of the knowledge stopped being oral.
- The system kept its applied focus: not rewriting for the sake of rewriting, but improving maintainability for working urban infrastructure.
For similar work, I help analyze inherited data systems, restore documentation, set up repositories and delivery processes, package operational knowledge, and reduce maintenance risk.