Russian city district list: from a failed SQL plan to n8n + Wikipedia API + OpenAI
This was a small urgent order with a very specific output: a list in the format region; city; city district for cities across Russia, and if a city has no district division, the row should be returned without a district value.
At the start, it looked like a "quick SQL on a familiar database" task. In practice, it became a good example of how a simple-looking export turns into source-data research, quality validation, and a full technical pivot during execution.
What mattered for the business
- Get a complete list for cities across Russia, not a partially correct export.
- Keep the output in a clear format the client could use immediately.
- Avoid delivering a file that looked "done" but was actually unreliable.
- Maintain transparent communication on timeline changes once it became clear the initial estimate was too optimistic.
- Finish with a usable result even if that required changing both the source and the processing logic.
From a business perspective, the key point was not to force the original "one SQL query" plan, but to avoid handing the client incorrect data. In tasks like this, that matters more than speed: a bad reference table breaks filters, segmentation, and downstream automations.
If you have a similar task (bulk reference table creation, non-standard exports, combining official and open sources, result quality validation), send the task via the brief form. I can build a working pipeline, not just "some export".
Before the implementation details, a quick terminology note. In Russia there is an older database called "КЛАДР" (a historical address classifier) and a newer state database called "ГАР" (the state address registry). These are common sources for address/reference tasks, but they do not guarantee that the data is stored in the exact business-ready format needed for a specific project.
It is also important to understand that Russia has both administrative division and municipal division, and they are not the same; there is no single "perfect" federal database where every city has the exact intra-city districts listed in one consistent format for this type of request.
What was planned first
Initially, I expected this to be solvable with a simple SQL query against "КЛАДР", which I had used before. The logic seemed straightforward: take the reference data, build a "region → city → district" structure, export CSV, and deliver.
Once I started working, it turned out that "КЛАДР" did not contain city district data in the form required for this task. At that point it was clear the "quick SQL" plan would not work and another source was needed.
Technical challenges: why the "ГАР" route did not work end-to-end
1. The right source in theory, but heavy in practice
Open-source research pointed to "ГАР" (the state address registry), which does have newer and more detailed data than "КЛАДР". The problem was scale: the archive was about 50 GB.
2. Downloading from outside Russia was unexpectedly tricky
One more surprise: the file index page was not accessible from outside Russia. But once a direct file link was obtained, the download itself worked (from another domain). So the data was technically reachable, but the path to it was non-obvious.
3. The archive could not be fully unpacked on a laptop
Even after downloading it, the next issue appeared: unpacking the archive in full was not possible because there was not enough free disk space on the laptop. The practical workaround was to read the archive and unpack it in batches (I processed roughly 10 regions at a time), then process and free space before the next batch.
4. The main issue: data quality/structure for the client's actual requirement
After partial processing of "ГАР", it became clear that even then the result could not be turned into a correct automatic district list for all cities:
- Some cities had district-like entries, some did not.
- Large cities (especially Moscow and Saint Petersburg) mixed districts, municipalities, and other types of intra-city division.
- Many other cities also had inconsistent structure, or no district information in the form the client needed.
This was the key decision point: technically, "something" was already being assembled, but the result could not be responsibly delivered as complete and accurate. A file could be generated, but the dataset was unreliable.
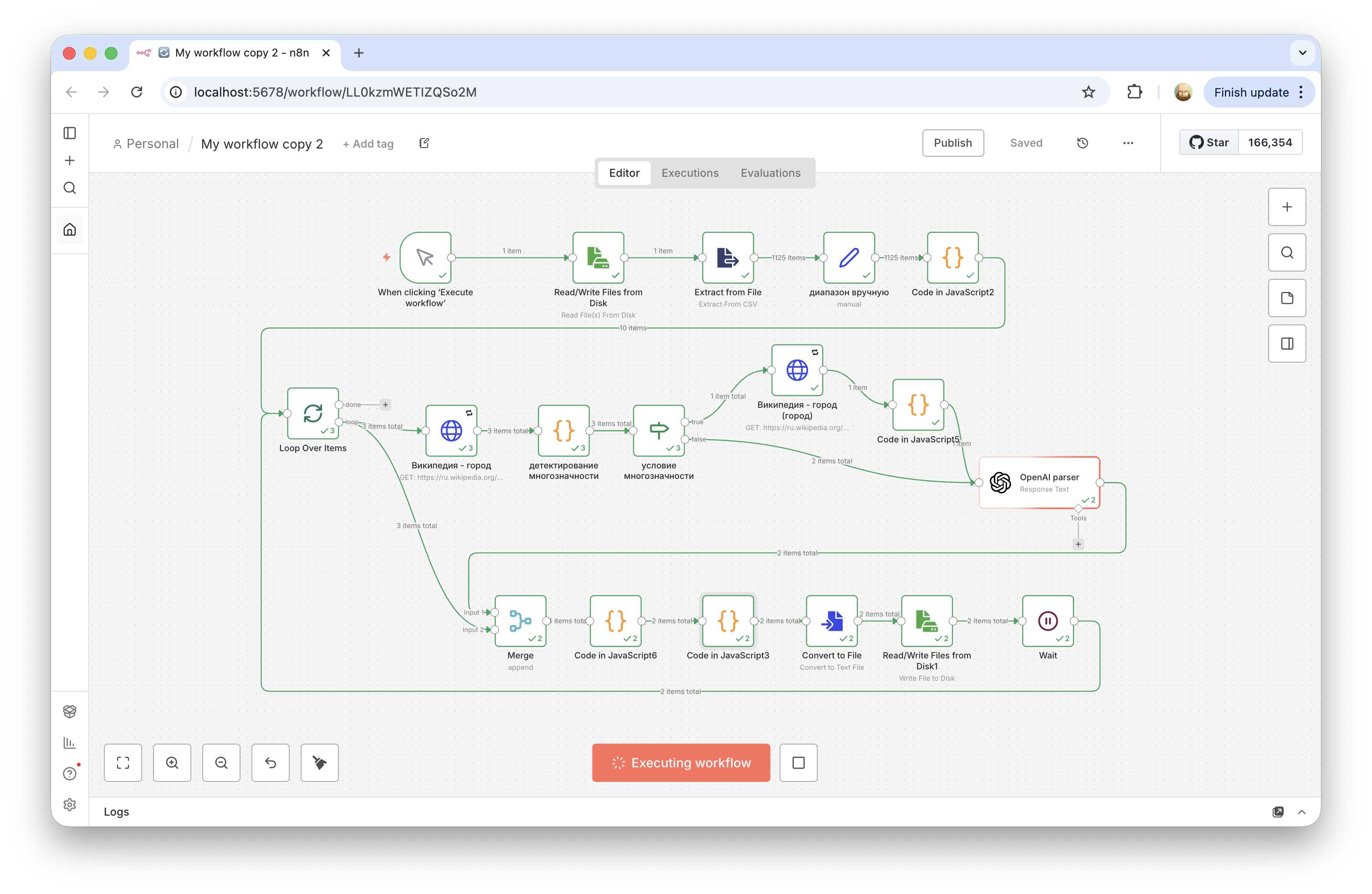
Solution pivot: n8n + Wikipedia API + OpenAI
The third approach was an n8n workflow. The input was a list of all Russian cities, and for each city the workflow did the following:
- Open the city's Wikipedia page.
- Fetch the article text via the Wikipedia API.
- Send the text to OpenAI with a prompt to extract intra-city districts/okrugs in a structured form.
- Assemble and save the final table.
In practice, this worked much better than expected: the result was almost ideal in both completeness and quality.
Additional challenges in the LLM-based approach
- For some city names, Wikipedia returned a disambiguation page instead of the city article. There were about two dozen such cases, so I added a separate branch in the workflow for them.
- For Moscow and Saint Petersburg, it was faster and more reliable to handle them separately by hand than to over-generalize everything into one extraction template.
- The result had to be checked not only for format, but also for semantics (whether the extracted entities were really city districts/okrugs and not just any administrative entities mentioned in the article).
Result
- The final file was complete and usable for the client.
- The task was completed even though the initial plan ("one SQL query") turned out to be wrong.
- The project produced a reusable n8n + API + LLM approach for situations where official registries do not provide the required business structure out of the box.
Practical takeaway
Even official databases do not always store data in the form the business actually needs. In this type of task, the key is not only to "get data", but to verify whether the source model matches the business question.
In this project, the path was longer than planned: first "КЛАДР", then an attempt with "ГАР", then n8n + Wikipedia + OpenAI. But that pivot is exactly what produced a workable result. In many projects, that is the real value: not forcing the first technical plan, but getting to a correct output.