Local automated English-to-Russian translation with Qwen 2.5 32B
The goal of this test was practical: to verify whether fully automated English-to-Russian translation is feasible with a local model, without relying on paid APIs for the main volume.
Qwen 2.5 32B was used as the base model. The task was not just to “get a translation”, but to build a production-like workflow for real document volumes: predictable speed, quality control, and clear economics.
This stage directly continues the OCR stage: OCR produced the source LaTeX from PDF, and this stage handled automated translation and quality polishing. Source context and an example of the untranslated block are in the DeepSeek OCR 2 post.
What mattered for the business
- Translate large EN content volumes into RU automatically, without manual paragraph-by-paragraph work.
- Reduce cost versus a “100% paid API” approach.
- Keep quality at a level suitable for publication and downstream use.
- Have built-in detection of bad chunks and process only the problematic subset separately.
The key idea: use local translation for the stable majority, and route a small difficult subset to a stronger (and more expensive) fallback channel.
If you have a similar task (bulk translation of documentation, knowledge base, catalog cards, website content) and need lower cost without quality loss, you can send details via the brief form.
Outcome
- Fully automated flow was implemented and run locally on Mac.
- On CPU, the workflow was impractical for production volumes due to latency.
- On GPU, speed and throughput became production-viable.
- About 95% of chunks were translated automatically without intervention.
- About 5% had artifacts: CJK symbols, untranslated fragments, or extra comments in output.
That 5% can be detected automatically and sent to a separate polishing route.
Economics
If you translate everything through paid APIs, cost scales linearly with volume. In the local approach, most cost is in setup and local compute, while per-run variable cost is much lower.
In practice, this gave a workable model:
- main volume translated locally (cheaper);
- only problematic 5% sent to paid API (more expensive per token, but limited scope);
- total pipeline cost significantly lower than “100% API”.
How the problematic 5% was handled
Problematic chunks were automatically flagged for re-translation:
- unexpected script/symbol detection (for example, CJK symbols in RU output);
- source-language leakage checks (large EN fragments in RU result);
- meta/commentary artifacts that should not appear in final content.
That small subset can then be sent to OpenAI API as a second stage: more expensive per chunk, but higher quality where local output is unstable. This yields a controlled hybrid pipeline: fast, cheaper on average, and high-quality final output.
Technical details
Below is the PoC setup that became the working baseline on Mac.
PoC goal and constraints
- Translate a LaTeX document with many headings, paragraphs, and especially footnotes, with high legal-semantic accuracy.
- Run locally on macOS without direct local tool installation.
Final model profile
The quality target profile for this PoC was Qwen2.5-32B-Instruct, quantized as Q4_K_M.
Model link: Qwen/Qwen2.5-32B-Instruct-GGUF.
Working LM Studio setup on this hardware: GPU offload max (UI showed 64/64), starting context 4096.
We also tested Q3_K_M: it was faster, but weaker on legal phrasing precision and terminology stability. Final quality baseline remained Q4_K_M.
Current translation flow
- Source is split into blocks by empty lines.
- Long blocks are split with sentence priority (
. ? !), with safe fallback by space/limit. - A single strict system prompt is used (no separate review/retry/heading modes).
\footnote{...}and links (\url,\href,\hyperref,\nolinkurl,\path) are not translated.
Validation and auto quality control
- Meta-commentary is rejected (
Note,Correction,Final, etc.). - Markdown code fences in output are rejected.
- English maritime keyword leakage in RU output is checked.
- CJK symbols, duplicate line breaks, and other “dirty output” patterns are detected.
Model experiments
qwen2.5:7b: faster, but weaker terminology and stability on complex paragraphs.qwen2.5:14b: better than 7b, but still had quality drift and multilingual leakage.qwen2.5:32b: significantly better quality, but much more demanding on memory/compute resources.
Why CPU was not viable and GPU became baseline
- On CPU, long chunks caused long timeouts/retries, making full runs impractical.
- Not only prompting mattered; resource profile and runtime tuning were critical.
- On Mac GPU with
Q4_K_M, throughput improved by several times at acceptable legal quality.
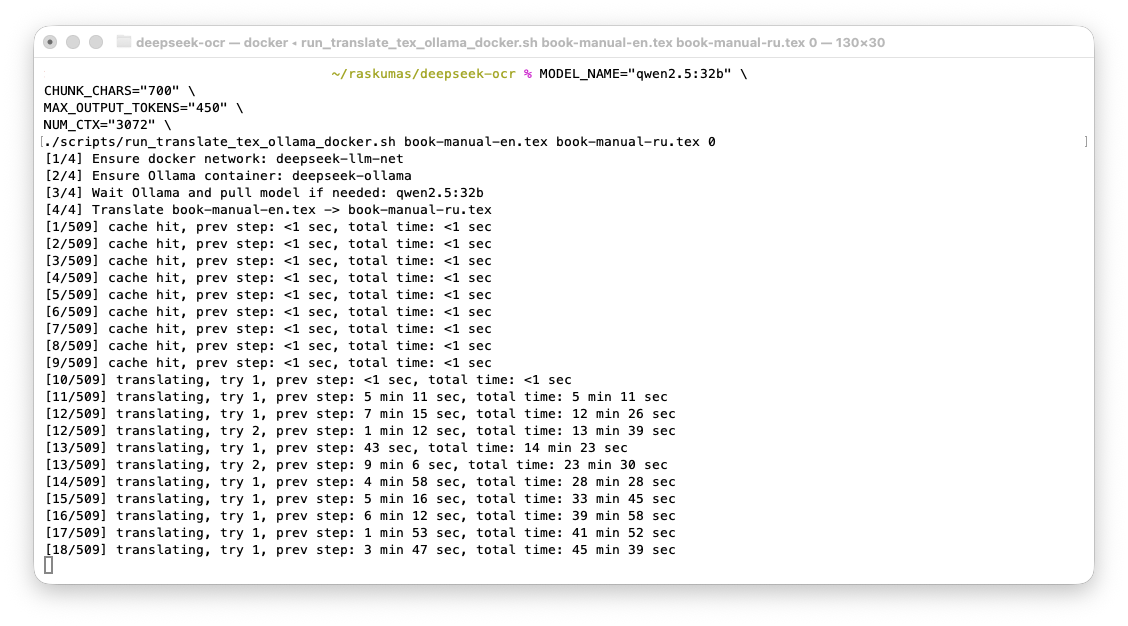
Figure 1. CPU run: one paragraph took roughly 5-9 minutes.
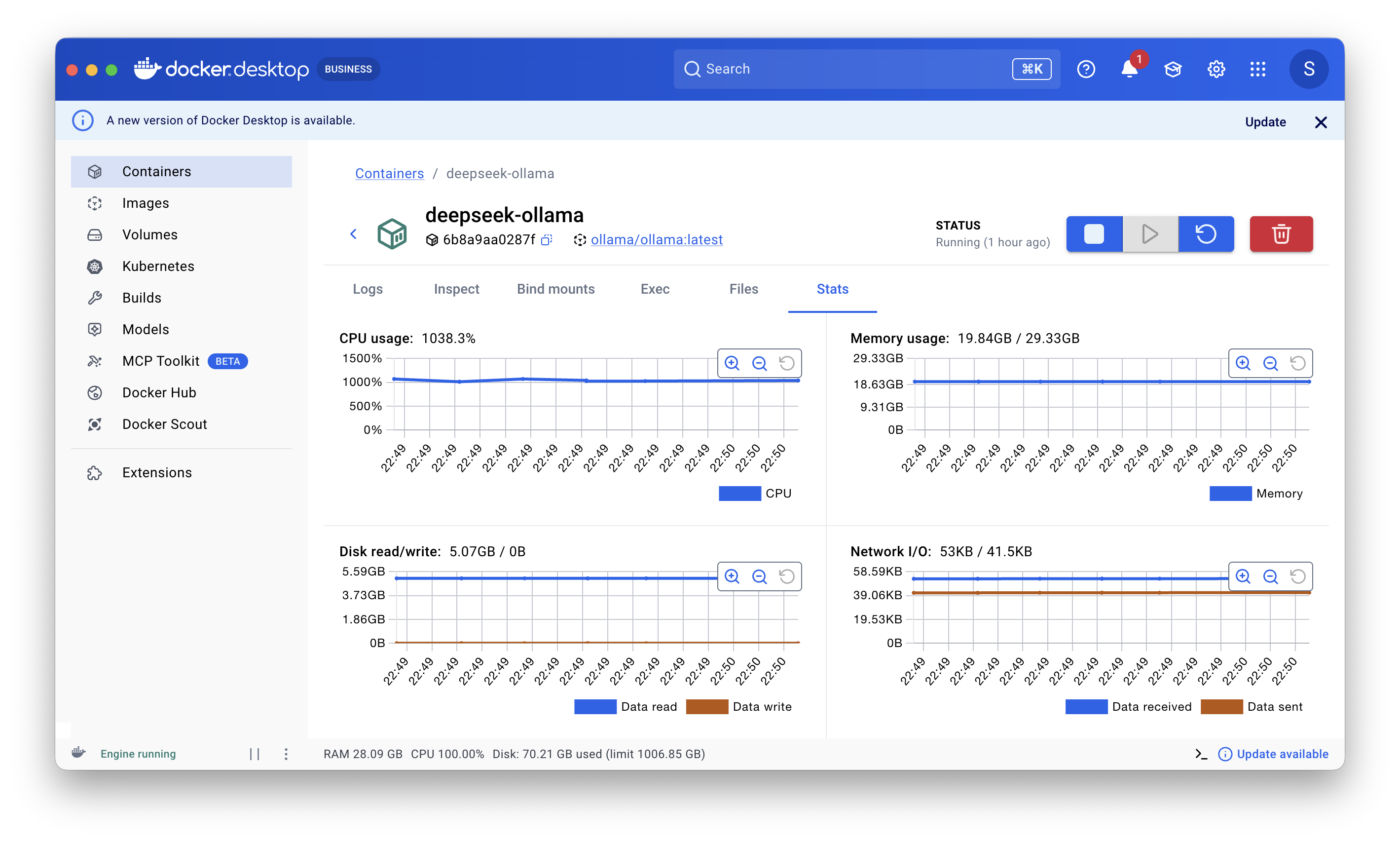
Figure 2. CPU run used Docker; memory usage was around 20 GB. GPU run was executed separately in LM Studio.
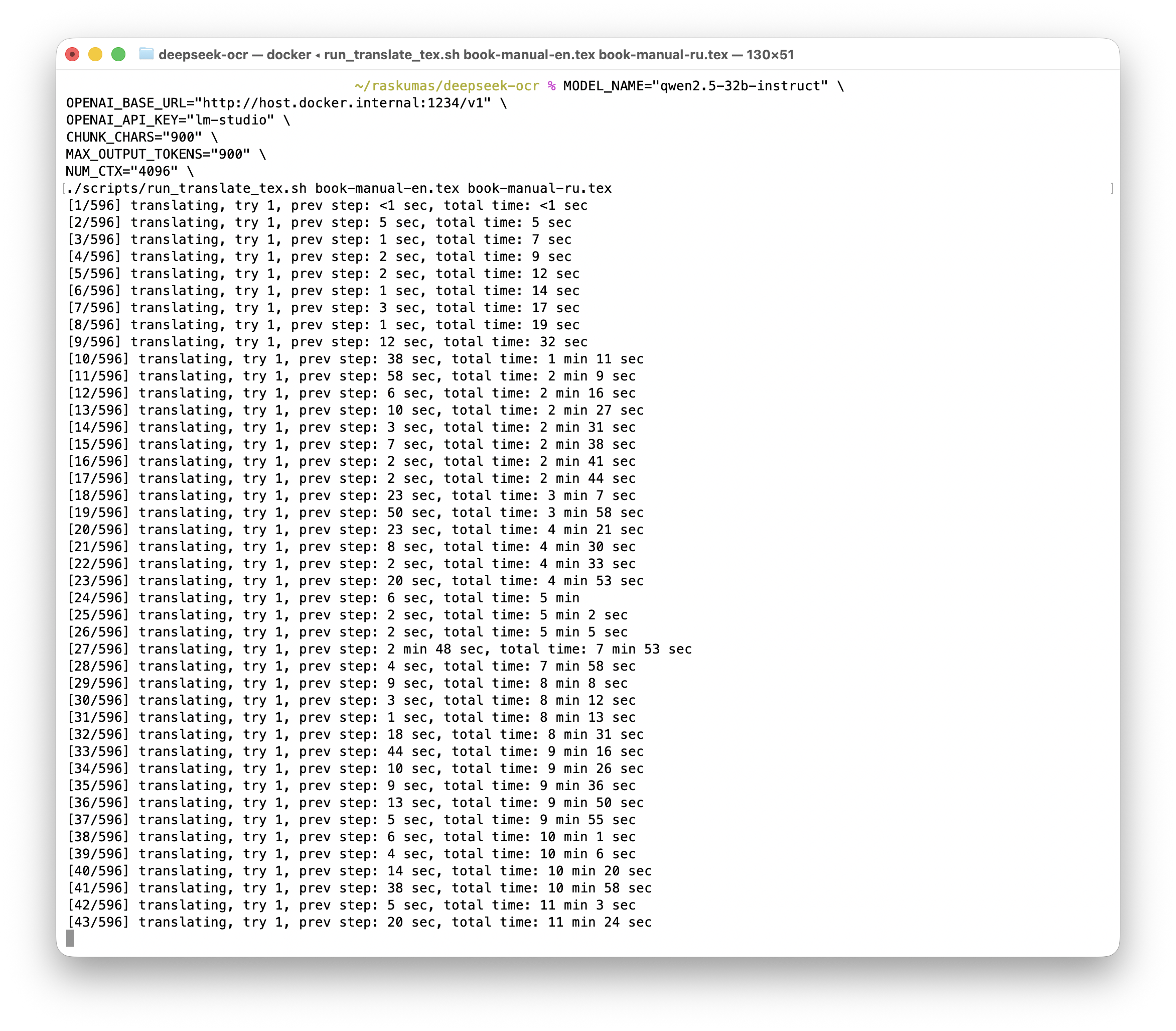
Figure 3. Accelerated profile: one paragraph took about 15 seconds.
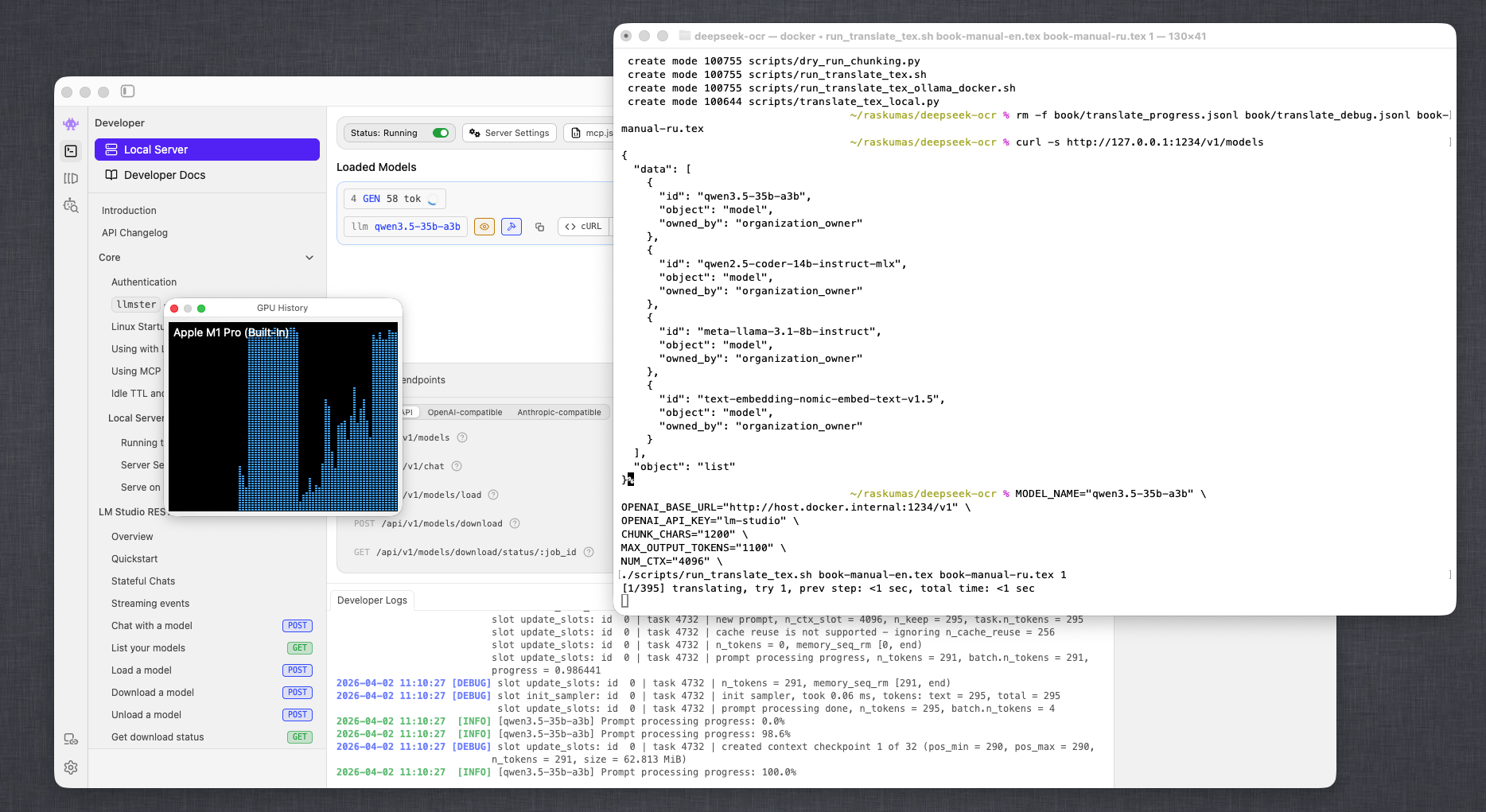
Figure 4. Sustained GPU utilization during the run (LM Studio + macOS System Monitor).
Inference settings and their impact
Quality on the first 12 lines improved significantly due to three combined factors: fewer model degrees of freedom (single strict system prompt, no review/retry/heading modes), cleaner input (only translatable text rather than full LaTeX markup), and strict output validation (meta/noise rejected and retried).
Beyond model choice, inference and pipeline parameters had strong impact:
temperature: main creativity/variance lever. Lower (around0.0) gave more stable legal phrasing and less noise.top_p: tail truncation. Withtemperature=0impact is small; with higher temperature, lowertop_pmakes style stricter but can cut good alternatives.max_tokens: response length cap. Too low causes truncation; too high does not improve quality directly but reduces cut-offs on long chunks.num_ctx: available context window. Larger improves coherence on long chunks but increases latency/load.4096was a good balance here.CHUNK_CHARS(pipeline parameter): translation chunk size. Larger gives more local context but raises timeout/degradation risk; smaller is more stable but can reduce cross-sentence coherence.
Bottom line: inference and chunking parameters influenced outcomes almost as much as model choice.
Final technical scheme
- Extract text -> translate -> assemble as the baseline flow.
- Output
.texis written from run start; if a chunk fails, fallback is written and the run continues. - After full coverage, quality-gate detects artifacts and builds a separate problematic-chunk queue.
- Only problematic chunks are polished (stronger local model or paid API), then final assembly is done.
Important: there was a direct attempt to translate raw LaTeX markup as-is, but that mode produced more hallucinations and structure breakage. The working approach was to extract only translatable text from LaTeX, translate it, then assemble the final document back with preserved markup.
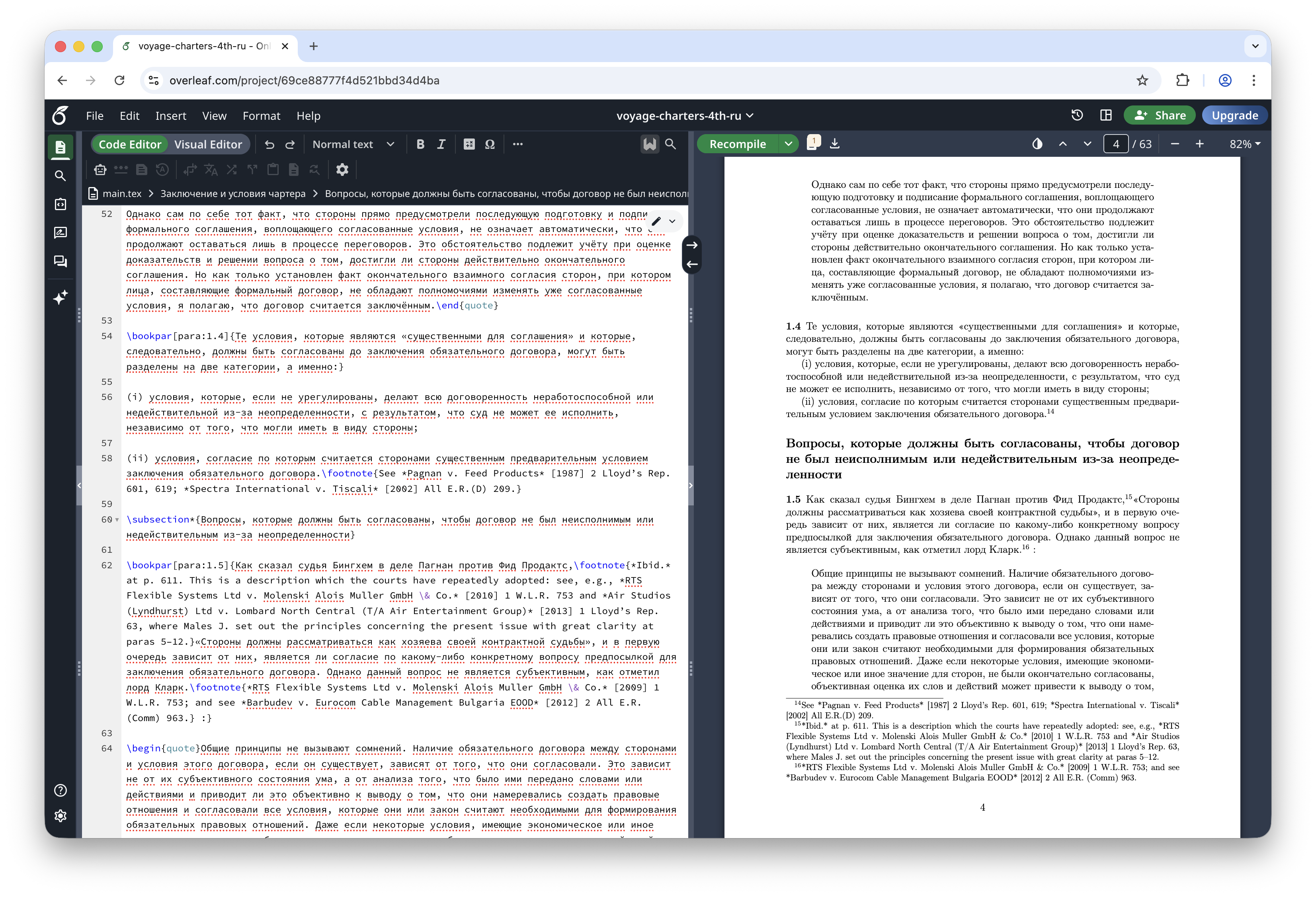
Figure 5. Final result: translated page in Overleaf (LaTeX + compiled PDF). The original untranslated block is shown in the OCR post.
Main technical takeaway: for this class of documents, the best practical compromise is local bulk translation on a 32B profile + automatic defect detection + targeted polishing of a small difficult subset.